Hadoop简介
Hadoop概念:
Hadoop是一个开源的,可靠的,可扩展的分布式计算框架。
- 允许使用简单的编程模型跨计算机集群分布式处理大型数据集
- 可扩展:从单个服务器扩展到数千台计算机,每台计算机都提供本地计算和存储
- 可靠的:不依赖硬件来提供高可用,而是在应用层检测和处理故障,从而在计算机集群之上提供高可用服务
Hadoop能做什么?
- 搭建大型数据仓库
- PB级数据的存储、处理、分析、统计等业务
Hadoop优势
- 高可靠
- 数据存储:数据块多副本
- 数据计算:某个节点崩溃,会自动重新调度作业计算
- 高扩展性
- 存储/计算资源不够时,可以横向的线性扩展机器
- 一个集群中可以包含数以千计的节点
- 集群可以使用廉价机器,成本低
- Hadoop生态系统成熟
2.Hadoop核心组件
Hadoop Common:hadoop核心组件
HDFS:分布式文件系统
- 源自于Google的GFS论文,论文发表于2003年10月
- HDFS是GFS的开源实现
- HDFS的特点:扩展性&容错性&海量数量存储
- 将文件切分成指定大小的数据块,并在多台机器上保存多个副本
- 数据切分,多副本、容错等操作对用户是透明的
Hadoop MapReduce:分布式计算框架
- 源于Google的MapReduce论文,发表于2004年12月
- MapReduce是GoogleMapReduce的开源实现
- MapReduce特点:扩展性&容错性&海量数据离线处理
Hadoop YARN:资源调度系统
- 负责整个集群资源的管理和调度
- YARN特点:扩展性&容错性&多框架资源统一调度
3.Hadoop生态系统
简介
Hadoop生态系统是一个很庞大的概念,Hadoop是其中最重要最基础的一个部分,生态系统中每一个子系统只解决某一个特点的问题域,不搞统一型的全能系统,而是小而精的多个小系统;
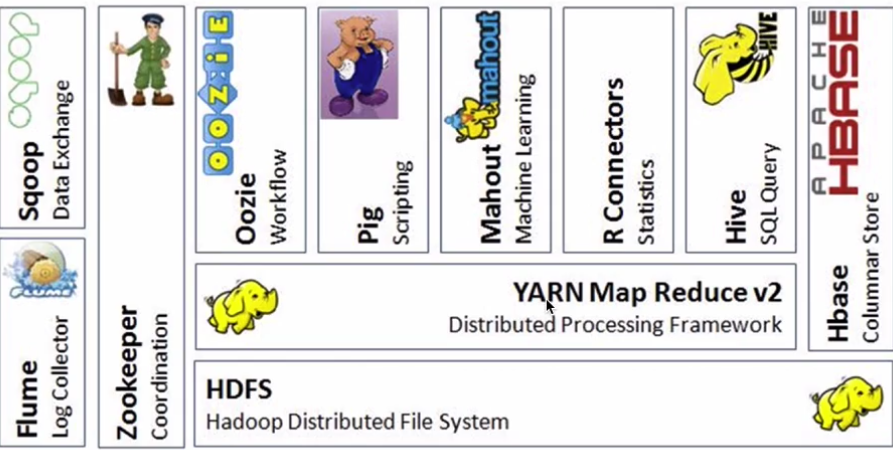
Hive:数据仓库
R:数据分析
Mahout:机器学习库
pig:脚本语言,跟Hive类似
Oozie:工作流引擎,管理作业执行顺序
Zookeeper:主节点挂掉自动选择从节点作为主的
Flume:日志收集框架
Sqoop:数据交换框架
Hbase:海量数据中的查询,相当于分布式文件系统中的数据库
Spark:分布式的计算框架,基于内存
- spark core
- spark sql
- spark streaming 准实时的一个标准的流式计算
- spark ML
Kafka:消息队列
Storm:分布式的流式计算框架
Flink:分布式的流式计算框架
Hadoop生态的特点
- 开源、社区活跃
- 囊括了大数据处理的方方面面
- 成熟的生态圈
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 zoubinbf@163.com

